
Shun Iwase, Zubair Irshad, Katherine Liu, Vitor Guizilini, Robert Lee, Takuya Ikeda, Ayako Amma, Koichi Nishiwaki, Kris Kitani, Rares Ambrus, Sergey Zakharov
CVPR 2025
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
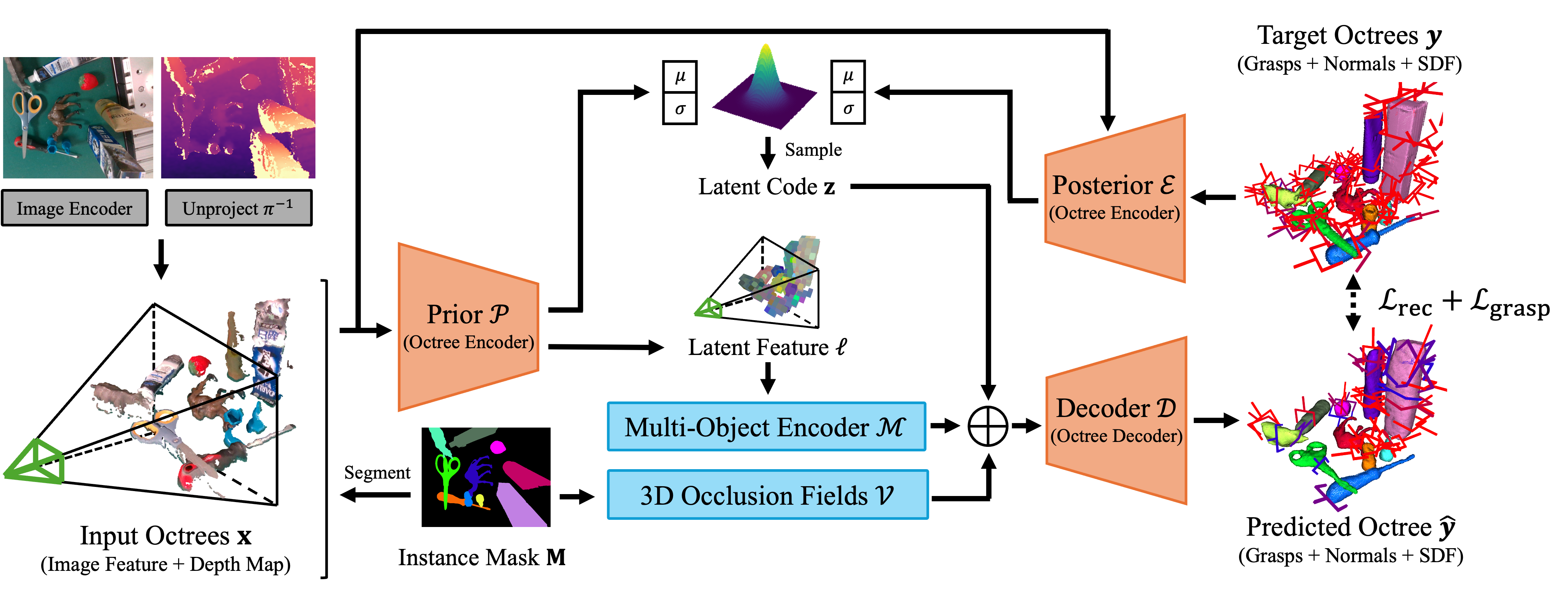
@InProceedings{Iwase_CVPR_2025, author = {Iwase, Shun and, Irshad, Zubair and Liu, Katherine and Guizilini, Vitor and Lee, Robert and Ikeda, Takuya and Amma, Ayako and Nishiwaki, Koichi and Kitani, Kris and Ambruș, Rareș and Zakharov, Sergey}, title = {ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping}, booktitle = {CVPR}, year = {2025} }
Jiahao Li, Haochen Wang, Muhammad Zubair Irshad, Igor Vasiljevic, Matthew R. Walter, Vitor Campagnolo Guizilini, Greg Shakhnarovich
arXiv 2025
We propose FastMap, a new global structure from motion method focused on speed and simplicity. Previous methods like COLMAP and GLOMAP are able to estimate high-precision camera poses, but suffer from poor scalability when the number of matched keypoint pairs becomes large. We identify two key factors leading to this problem: poor parallelization and computationally expensive optimization steps. To overcome these issues, we design an SfM framework that relies entirely on GPU-friendly operations, making it easily parallelizable. Moreover, each optimization step runs in time linear to the number of image pairs, independent of keypoint pairs or 3D points. Through extensive experiments, we show that FastMap is faster than COLMAP and GLOMAP on large-scale scenes with comparable pose accuracy.

@article{2505.04612v1, Author = {Jiahao Li and Haochen Wang and Muhammad Zubair Irshad and Igor Vasiljevic and Matthew R. Walter and Vitor Campagnolo Guizilini and Greg Shakhnarovich}, Title = {FastMap: Revisiting Dense and Scalable Structure from Motion}, Eprint = {2505.04612v1}, ArchivePrefix = {arXiv}, PrimaryClass = {cs.CV}, Year = {2025}, Month = {May}, Url = {http://arxiv.org/abs/2505.04612v1}, File = {2505.04612v1.pdf} }
Cameron Smith, Basile Van Hoorick, Vitor Guizilini, Yue Wang
arXiv 2025
Motion serves as a powerful cue for scene perception and understanding by separating independently moving surfaces and organizing the physical world into distinct entities. We introduce SIRE, a self-supervised method for motion discovery of objects and dynamic scene reconstruction from casual scenes by learning intrinsic rigidity embeddings from videos. Our method trains an image encoder to estimate scene rigidity and geometry, supervised by a simple 4D reconstruction loss: a least-squares solver uses the estimated geometry and rigidity to lift 2D point track trajectories into SE(3) tracks, which are simply re-projected back to 2D and compared against the original 2D trajectories for supervision. Crucially, our framework is fully end-to-end differentiable and can be optimized either on video datasets to learn generalizable image priors, or even on a single video to capture scene-specific structure - highlighting strong data efficiency. We demonstrate the effectiveness of our rigidity embeddings and geometry across multiple settings, including downstream object segmentation, SE(3) rigid motion estimation, and self-supervised depth estimation. Our findings suggest that SIRE can learn strong geometry and motion rigidity priors from video data, with minimal supervision.
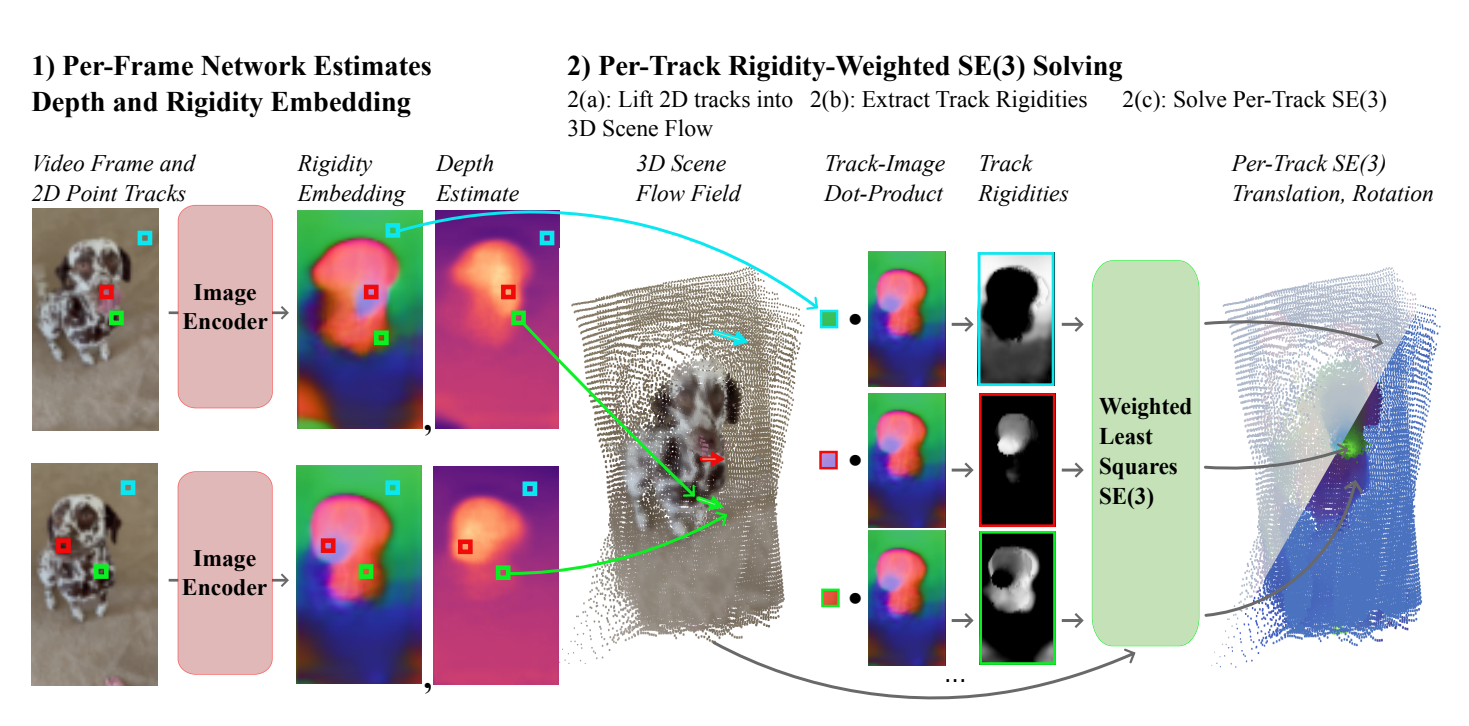
@misc{tri-sire, title={SIRE: SE(3) Intrinsic Rigidity Embeddings}, author={Cameron Smith and Basile Van Hoorick and Vitor Guizilini and Yue Wang}, eprint={2503.07739}, archivePrefix={arXiv}, primaryClass={cs.CV}, year={2025} }
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, Yue Wang
ICLR 2025
Understanding the physical world is a fundamental challenge in embodied AI, critical for enabling agents to perform complex tasks and operate safely in real-world environments. While Vision-Language Models (VLMs) have shown great promise in reasoning and task planning for embodied agents, their ability to comprehend physical phenomena remains extremely limited. To close this gap, we introduce PhysBench, a comprehensive benchmark designed to evaluate VLMs physical world understanding capability across a diverse set of tasks. PhysBench contains 10,002 entries of interleaved video-image-text data, categorized into four major domains: physical object properties, physical object relationships, physical scene understanding, and physics-based dynamics, further divided into 19 subclasses and 8 distinct capability dimensions. Our extensive experiments, conducted on 75 representative VLMs, reveal that while these models excel in common-sense reasoning, they struggle with understanding the physical world -- likely due to the absence of physical knowledge in their training data and the lack of embedded physical priors. To tackle the shortfall, we introduce PhysAgent, a novel framework that combines the generalization strengths of VLMs with the specialized expertise of vision models, significantly enhancing VLMs physical understanding across a variety of tasks, including an 18.4\% improvement on GPT-4o. Furthermore, our results demonstrate that enhancing VLMs physical world understanding capabilities can help embodied agents such as MOKA. We believe that PhysBench and PhysAgent offer valuable insights and contribute to bridging the gap between VLMs and physical world understanding.

@inproceedings{tri-physbench, author={Wei Chow and Jiageng Mao and Boyi Li and Daniel Seita and Vitor Guizilini and Yue Wang}, title={PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding}, booktitle = {Proceedings of the International Conference on Learning Representations (ICLR)}, year={2025} }
Vitor Guizilini, Muhammad Zubair Irshad, Dian Chen, Greg Shakhnarovich, Rares Ambrus
CVPR 2025
Current methods for 3D scene reconstruction from sparse posed images employ intermediate 3D representations such as neural fields, voxel grids, or 3D Gaussians, to achieve multi-view consistent scene appearance and geometry. In this paper we introduce MVGD, a diffusion-based architecture capable of direct pixel-level generation of images and depth maps from novel viewpoints, given an arbitrary number of input views. Our method uses raymap conditioning to both augment visual features with spatial information from different viewpoints, as well as to guide the generation of images and depth maps from novel views. A key aspect of our approach is the multi-task generation of images and depth maps, using learnable task embeddings to guide the diffusion process towards specific modalities. We train this model on a collection of more than 60 million multi-view samples from publicly available datasets, and propose techniques to enable efficient and consistent learning in such diverse conditions. We also propose a novel strategy that enables the efficient training of larger models by incrementally fine-tuning smaller ones, with promising scaling behavior. Through extensive experiments, we report state-of-the-art results in multiple novel view synthesis benchmarks, as well as multi-view stereo and video depth estimation.

@inproceedings{tri-mvgd, author={Vitor Guizilini and Muhammad Zubair Irshad and Dian Chen and Greg Shakhnarovich and Rares Ambrus}, title={Zero-Shot Novel View and Depth Synthesis with Multi-View Geometric Diffusion}, booktitle = {Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2025} }
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Vitor Guizilini, Yue Wang, Matteo Poggi, Yiyi Liao
CVPR 2025
This work addresses the challenge of streamed video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. We argue that sharing contextual information between frames or clips is pivotal in fostering temporal consistency. Thus, instead of directly developing a depth estimator from scratch, we reformulate this predictive task into a conditional generation problem to provide contextual information within a clip and across clips. Specifically, we propose a consistent context-aware training and inference strategy for arbitrarily long videos to provide cross-clip context. We sample independent noise levels for each frame within a clip during training while using a sliding window strategy and initializing overlapping frames with previously predicted frames without adding noise. Moreover, we design an effective training strategy to provide context within a clip. Extensive experimental results validate our design choices and demonstrate the superiority of our approach, dubbed ChronoDepth.
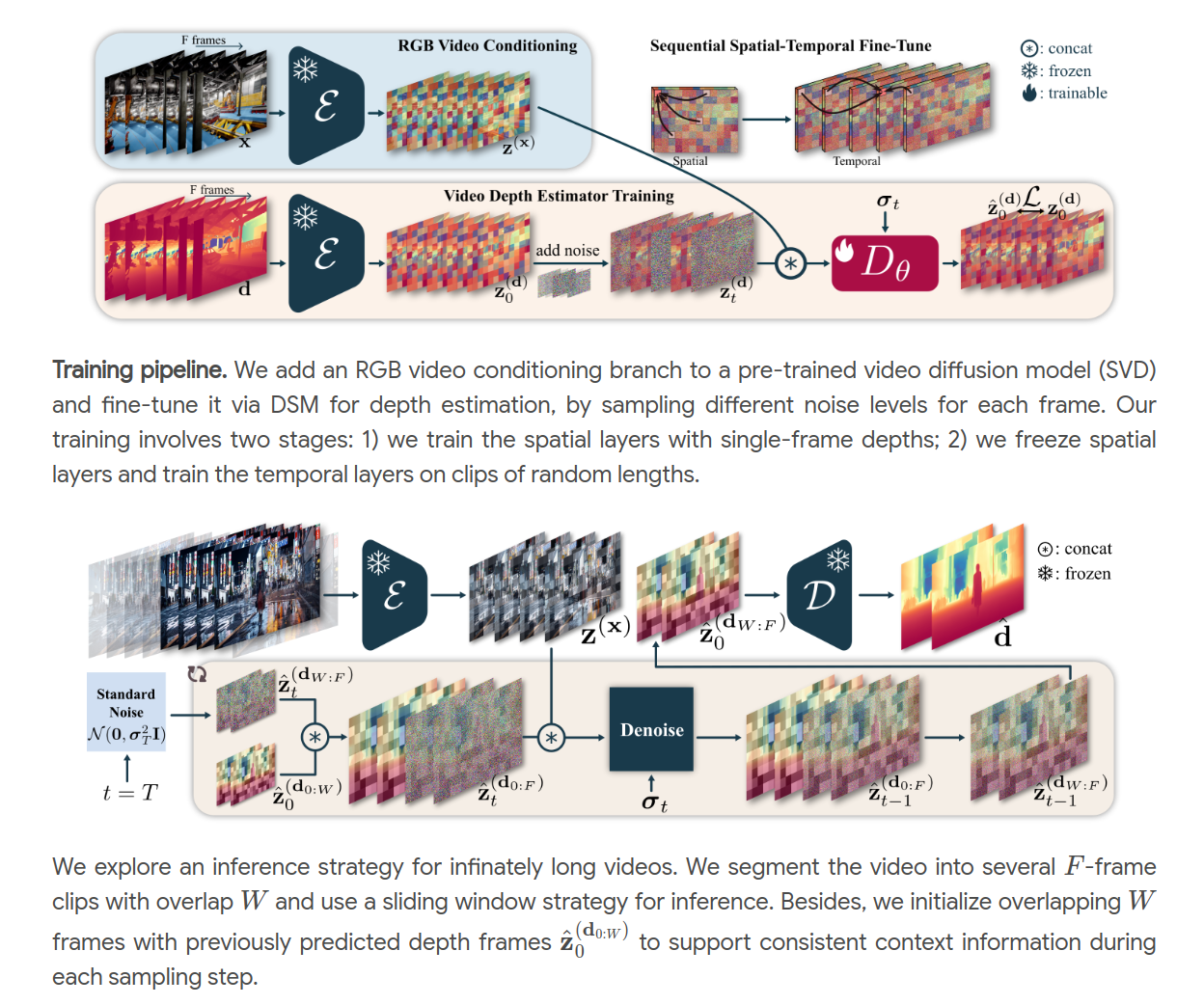
@inproceedings{tri-chronodepth, author={Jiahao Shao and Yuanbo Yang and Hongyu Zhou and Youmin Zhang and Yujun Shen and Vitor Guizilini and Yue Wang and Matteo Poggi and Yiyi Liao}, title={Learning Temporally Consistent Video Depth from Video Diffusion Priors}, booktitle = {Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2025} }
Jiageng Mao, Siheng Zhao, Siqi Song, Tianheng Shi, Junjie Ye, Mingtong Zhang, Haoran Geng, Jitendra Malik, Vitor Guizilini, Yue Wang
arXiv 2024
Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
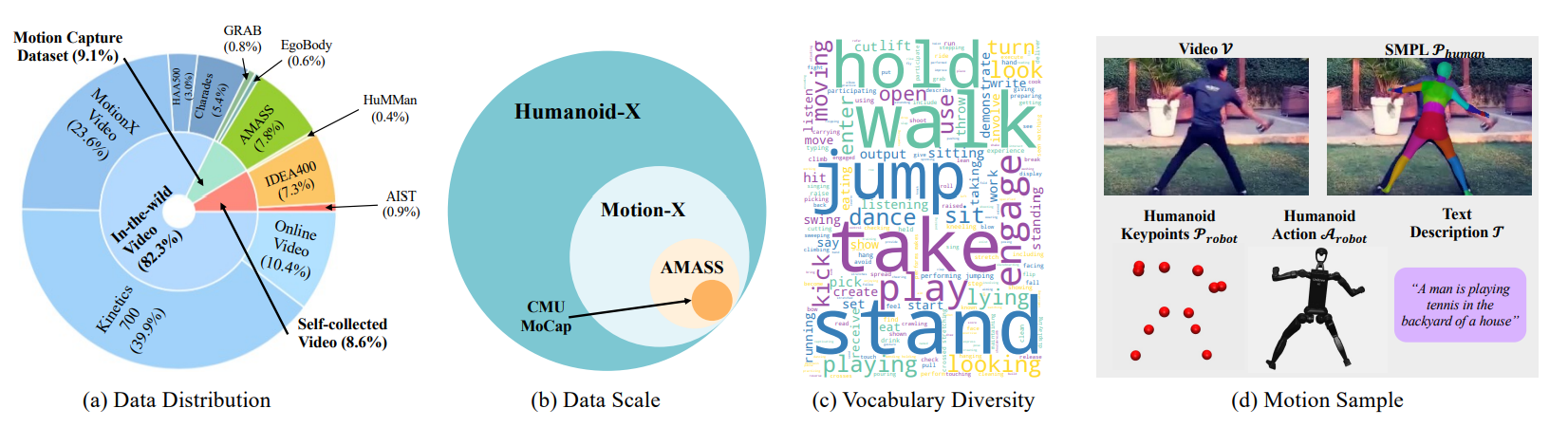
@misc{tri-humanoid, title={Learning from Massive Human Videos for Universal Humanoid Pose Control}, author={Jiageng Mao and Siheng Zhao and Siqi Song and Tianheng Shi and Junjie Ye and Mingtong Zhang and Haoran Geng and Jitendra Malik and Vitor Guizilini and Yue Wang}, eprint={2412.14172}, archivePrefix={arXiv}, primaryClass={cs.CV}, year={2024} }
Artem Lukoianov, Haitz Borde, Kristjan Greenewald, Vitor Guizilini, Timur Bagautdinov, Vincent Sitzmann, Justin Solomon
NeurIPS 2024
While 2D diffusion models generate realistic, high-detail images, 3D shape generation methods like Score Distillation Sampling (SDS) built on these 2D diffusion models produce cartoon-like, over-smoothed shapes. To help explain this discrepancy, we show that the image guidance used in Score Distillation can be understood as the velocity field of a 2D denoising generative process, up to the choice of a noise term. In particular, after a change of variables, SDS resembles a high-variance version of Denoising Diffusion Implicit Models (DDIM) with a differently-sampled noise term: SDS introduces noise i.i.d. randomly at each step, while DDIM infers it from the previous noise predictions. This excessive variance can lead to over-smoothing and unrealistic outputs. We show that a better noise approximation can be recovered by inverting DDIM in each SDS update step. This modification makes SDS generative process for 2D images almost identical to DDIM. In 3D, it removes over-smoothing, preserves higher-frequency detail, and brings the generation quality closer to that of 2D samplers. Experimentally, our method achieves better or similar 3D generation quality compared to other state-of-the-art Score Distillation methods, all without training additional neural networks or multi-view supervision, and providing useful insights into relationship between 2D and 3D asset generation with diffusion models.

@inproceedings{lukoianov2024score, author={Artem Lukoianov and Haitz Sáez de Ocáriz Borde and Kristjan Greenewald and Vitor Campagnolo Guizilini and Timur Bagautdinov and Vincent Sitzmann and Justin Solomon}, title={Score Distillation via Reparametrized DDIM}, booktitle = {Proceedings of the Conference on Neural Information and Processing Systems (NeurIPS)}, year={2024} }

Haoxi Ran, Vitor Guizilini, Yue Wang
CVPR 2024
Diffusion models (DMs) excel in photo-realistic image synthesis, but their adaptation to LiDAR scene generation poses a substantial hurdle. This is primarily because DMs operating in the point space struggle to preserve the curve-like patterns and 3D geometry of LiDAR scenes, which consumes much of their representation power. In this paper, we propose LiDAR Diffusion Models (LiDMs) to generate LiDAR-realistic scenes from a latent space tailored to capture the realism of LiDAR scenes by incorporating geometric priors into the learning pipeline. Our method targets three major desiderata: pattern realism, geometry realism, and object realism. Specifically, we introduce curve-wise compression to simulate real-world LiDAR patterns, point-wise coordinate supervision to learn scene geometry, and patch-wise encoding for a full 3D object context. With these three core designs, our method achieves competitive performance on unconditional LiDAR generation in 64-beam scenario and state of the art on conditional LiDAR generation, while maintaining high efficiency compared to point-based DMs (up to 107× faster). Furthermore, by compressing LiDAR scenes into a latent space, we enable the controllability of DMs with various conditions such as semantic maps, camera views, and text prompts.

@misc{ran2024lidm, author={Haoxi Ran and Vitor Guizilini and Yue Wang}, title={Towards Realistic Scene Generation with LiDAR Diffusion Models}, booktitle = {Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2024} }
Shun Iwase, Katherine Liu, Vitor Guizilini, Adrien Gaidon, Kris Kitani, Rares Ambrus, Sergey Zakharov
ECCV 2024
We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a naive 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability.

@misc{iwase2024zeroshot, title={Zero-Shot Multi-Object Shape Completion}, author={Shun Iwase and Katherine Liu and Vitor Guizilini and Adrien Gaidon and Kris Kitani and Rares Ambrus and Sergey Zakharov}, eprint={2403.14628}, archivePrefix={arXiv}, primaryClass={cs.CV} year={2024}, }
Vitor Guizilini, Igor Vasiljevic, Dian Chen, Rares Ambrus, Adrien Gaidon
ICCV 2023
Differentiable volumetric rendering is a powerful paradigm for 3D reconstruction and novel view synthesis. However, standard volume rendering approaches struggle with degenerate geometries in the case of limited viewpoint diversity, a common scenario in robotics applications. In this work, we propose to use the multi-view photometric objective from the self-supervised depth estimation literature as a geometric regularizer for volumetric rendering, significantly improving novel view synthesis without requiring additional information. Building upon this insight, we explore the explicit modeling of scene geometry using a generalist Transformer, jointly learning a radiance field as well as depth and light fields with a set of shared latent codes. We demonstrate that sharing geometric information across tasks is mutually beneficial, leading to improvements over single-task learning without an increase in network complexity. Our DeLiRa architecture achieves state-of-the-art results on the ScanNet benchmark, enabling high quality volumetric rendering as well as real-time novel view and depth synthesis in the limited viewpoint diversity setting.

@inproceedings{tri-zerodepth, title={Towards Zero-Shot Scale-Aware Monocular Depth Estimation}, author={Guizilini, Vitor and Vasiljevic, Igor and Chen, Dian and Ambrus, Rares and Gaidon, Adrien}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, month={October}, year={2023}, }
Takayuki Kanai, Igor Vasiljevic, Vitor Guizilini, Adrien Gaidon, Rares Ambrus
IROS 2023
Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization.

@inproceedings{tri_sesc_iros23, author = {Takayuki Kanai and Igor Vasiljevic and Vitor Guizilini and Adrien Gaidon and Rares Ambrus}, title = {Robust Self-Supervised Extrinsic Self-Calibration}, booktitle = {The IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2023} }
Dian Chen, Jie Li, Vitor Guizilini, Rares Ambrus, Adrien Gaidon
CVPR 2023
Autonomous vehicles and robots need to operate over a wide variety of scenarios in order to complete tasks efficiently and safely. Multi-camera self-supervised monocular depth estimation from videos is a promising way to reason about the environment, as it generates metrically scaled geometric predictions from visual data without requiring additional sensors. However, most works assume well-calibrated extrinsics to fully leverage this multi-camera setup, even though accurate and efficient calibration is still a challenging problem. In this work, we introduce a novel method for extrinsic calibration that builds upon the principles of self-supervised monocular depth and ego-motion learning. Our proposed curriculum learning strategy uses monocular depth and pose estimators with velocity supervision to estimate extrinsics, and then jointly learns extrinsic calibration along with depth and pose for a set of overlapping cameras rigidly attached to a moving vehicle. Experiments on a benchmark multi-camera dataset (DDAD) demonstrate that our method enables self-calibration in various scenes robustly and efficiently compared to a traditional vision-based pose estimation pipeline. Furthermore, we demonstrate the benefits of extrinsics self-calibration as a way to improve depth prediction via joint optimization.
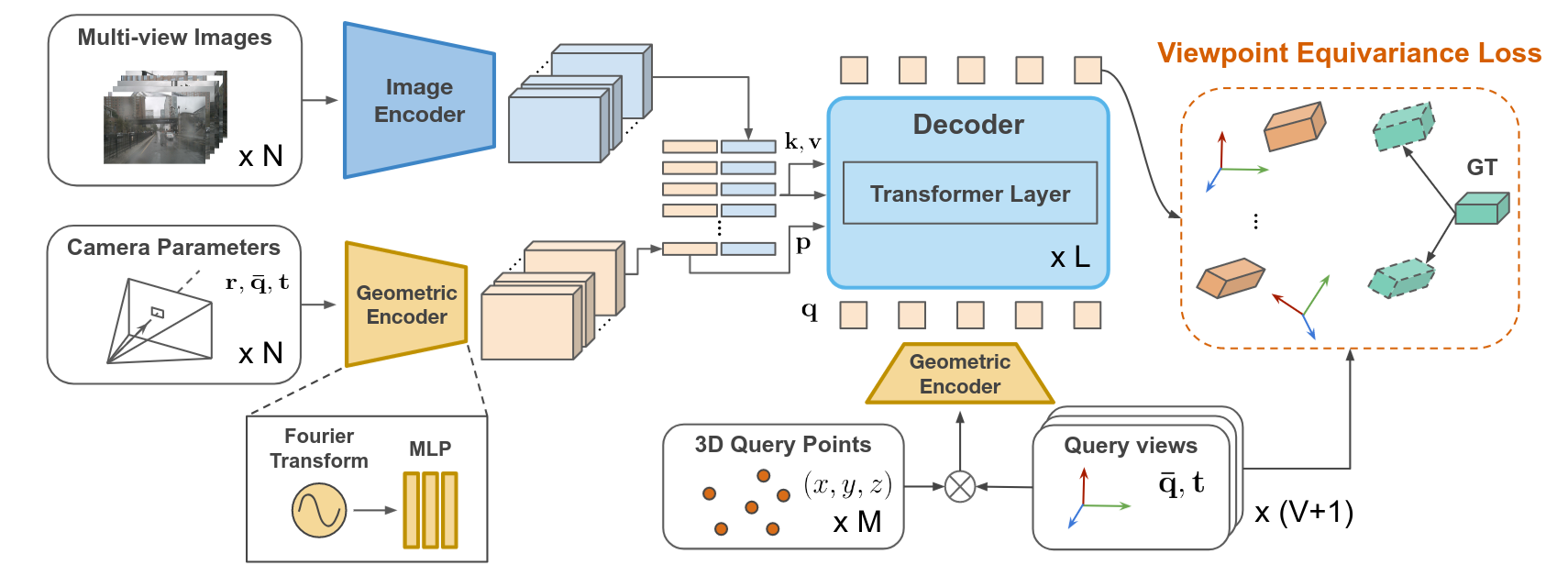
@inproceedings{chen2023viewpoint, title={Viewpoint Equivariance for Multi-View 3D Object Detection}, author={Chen, Dian and Li, Jie and Guizilini, Vitor and Ambrus, Rares and Gaidon, Adrien}, booktitle = {Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2023} }

Vitor Guizilini, Igor Vasiljevic, Jiading Fang, Rares Ambrus, Sergey Zakharov, Vincent Sitzmann, Adrien Gaidon
ICCV 2023
Differentiable volumetric rendering is a powerful paradigm for 3D reconstruction and novel view synthesis. However, standard volume rendering approaches struggle with degenerate geometries in the case of limited viewpoint diversity, a common scenario in robotics applications. In this work, we propose to use the multi-view photometric objective from the self-supervised depth estimation literature as a geometric regularizer for volumetric rendering, significantly improving novel view synthesis without requiring additional information. Building upon this insight, we explore the explicit modeling of scene geometry using a generalist Transformer, jointly learning a radiance field as well as depth and light fields with a set of shared latent codes. We demonstrate that sharing geometric information across tasks is mutually beneficial, leading to improvements over single-task learning without an increase in network complexity. Our DeLiRa architecture achieves state-of-the-art results on the ScanNet benchmark, enabling high quality volumetric rendering as well as real-time novel view and depth synthesis in the limited viewpoint diversity setting.

@inproceedings{tri_delira, author = {Vitor Guizilini and Igor Vasiljevic and Jiading Fang and Rares Ambrus and Sergey Zakharov and Vincent Sitzmann and Adrien Gaidon}, title = {DeLiRa: Self-Supervised Depth, Light, and Radiance Fields}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2023} }
Vitor Guizilini, Igor Vasiljevic, Jiading Fang, Rares Ambrus, Greg Shakhnarovich, Matthew Walter, Adrien Gaidon
ECCV 2022
Modern 3D computer vision leverages learning to boost geometric reasoning, mapping image data to classical structures such as cost volumes or epipolar constraints to improve matching. These architectures are specialized according to the particular problem, and thus require significant task-specific tuning, often leading to poor domain generalization performance. Recently, generalist Transformer architectures have achieved impressive results in tasks such as optical flow and depth estimation by encoding geometric priors as inputs rather than as enforced constraints. In this paper, we extend this idea and propose to learn an implicit, multi-view consistent scene representation, introducing a series of 3D data augmentation techniques as a geometric inductive prior to increase view diversity. We also show that introducing view synthesis as an auxiliary task further improves depth estimation. Our Depth Field Networks (DeFiNe) achieve state-of-the-art results in stereo and video depth estimation without explicit geometric constraints, and improve on zero-shot domain generalization by a wide margin.

@inproceedings{tri_define, author = {Vitor Guizilini and Igor Vasiljevic and Jiading Fang and Rares Ambrus and Greg Shakhnarovich and Matthew Walter and Adrien Gaidon}, title = {Depth Field Networks for Generalizable Multi-view Scene Representation}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2022}, }
